
Client Overview
Client
A growing Video on Demand (VOD) platform using Kernel Video Sharing (KVS).
Industry
Digital Entertainment, Funtech
The client operates a VOD platform based on KVS (our partners). Initially, the project was deployed on two servers with minimal architecture distribution. One server for the KVS script application, one server for the database.
Despite powerful mid-range servers, the unoptimized projects model quickly exhausted given hardware resources. CPU utilization was disproportionate to the generated traffic. It became clear that the most powerful server would not be able to handle the project’s requirements. The client was not prepared to face such a problem.
Key business operations
- On-demand video hosting with a growing global user base.
- Heavy demand for scalable computing resources.
A business that ignores infrastructure early will face scaling issues later on.

Challenges
Performance Bottlenecks
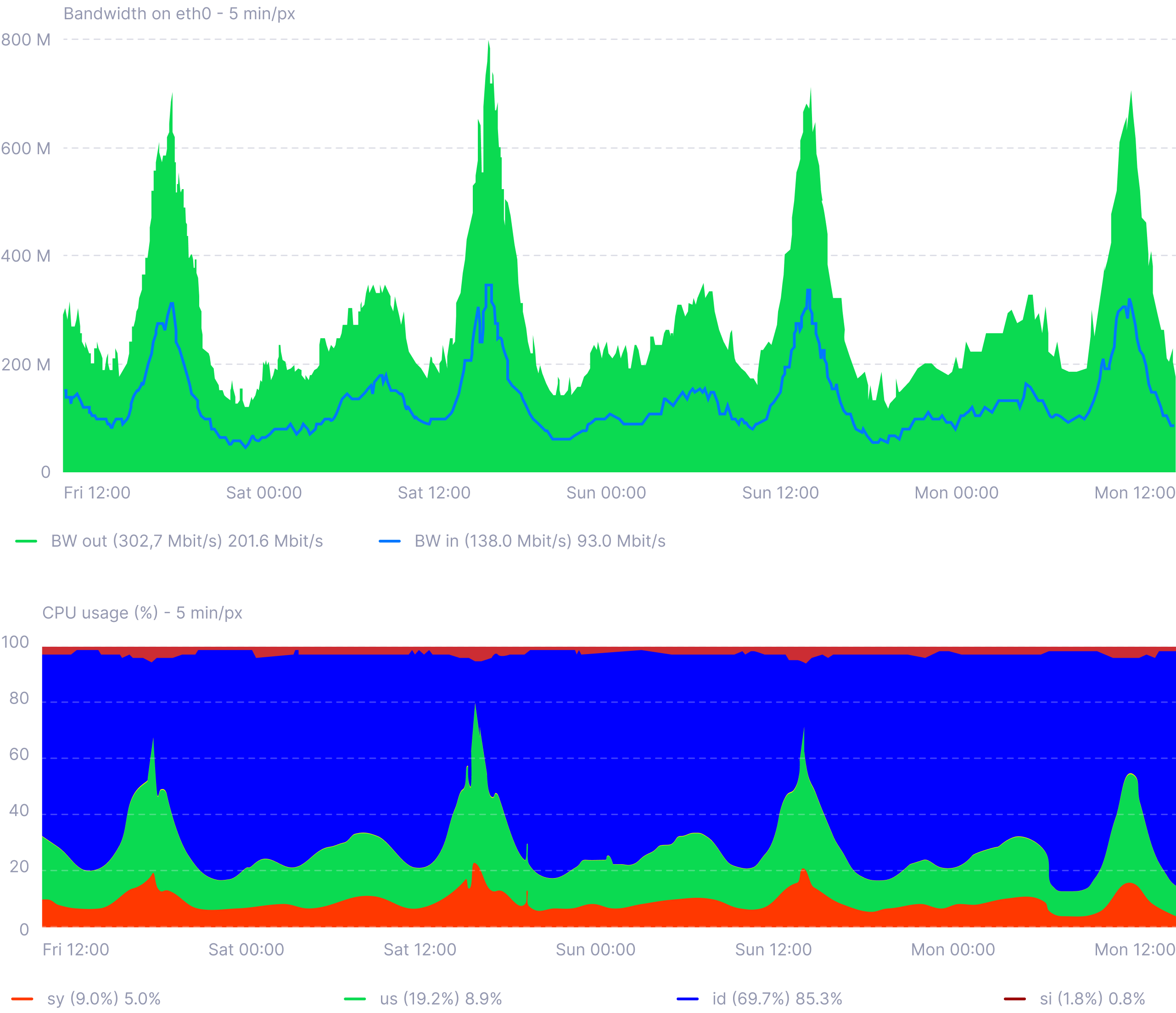
As traffic on the platform increased to 270Mb/s, the existing infrastructure struggled to keep up, leading to serious performance bottlenecks. The single-server setup was overwhelmed, with CPU limitations causing noticeable slowdowns and significant degradation of the web resource during prime time.
Illustration below: CDN traffic lost half of the value when Web resource visits chart dropped close to zero. This shows that even a server working at half capacity may bring zero profits.

Limited Scalability
Scalability was another major issue. The platform relied on vertical scaling, meaning that the only way to handle more traffic was to upgrade the existing server hardware. However, this approach had both cost and performance limits. The infrastructure was not designed for horizontal scaling, which would allow traffic to be distributed efficiently across multiple servers.
Unoptimized Architecture
Finally, the platform’s architecture was unoptimized. These inefficiencies compounded over time, making it increasingly difficult for the system to support the growing user base.
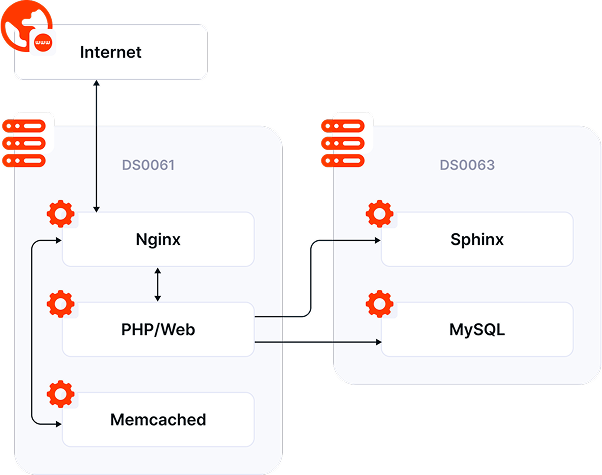
Business Impact
- Increasing operational costs due to the need for high-performance servers сombined with low efficiency.
- Frequent downtimes, leading to user dissatisfaction and potential revenue loss.
- Inefficient resource utilization, requiring an overhaul of the infrastructure.
Solution
First of all, we noticed the problem and proactively came to the client with a designed solution. Our proposition was to implement a multi-phase optimization approach instead of simply upgrading hardware.
Performance Analysis & Caching Implementation
- Conducted a full system audit, identifying database bottlenecks.
- Introduced multi-level caching to reduce database load.
- Refactored the project’s structure, separating heavy requests to dedicated handlers.
- Optimized file storage for improved efficiency. These steps led to an increase in outgoing traffic to 800Mb/s from the same stale flat architecture.
- Performed OS fine-tuning suitable to the current load of the server.
As a result, CPU usage was reduced by 40% with the same traffic, improving the usability of the web service for the end user.
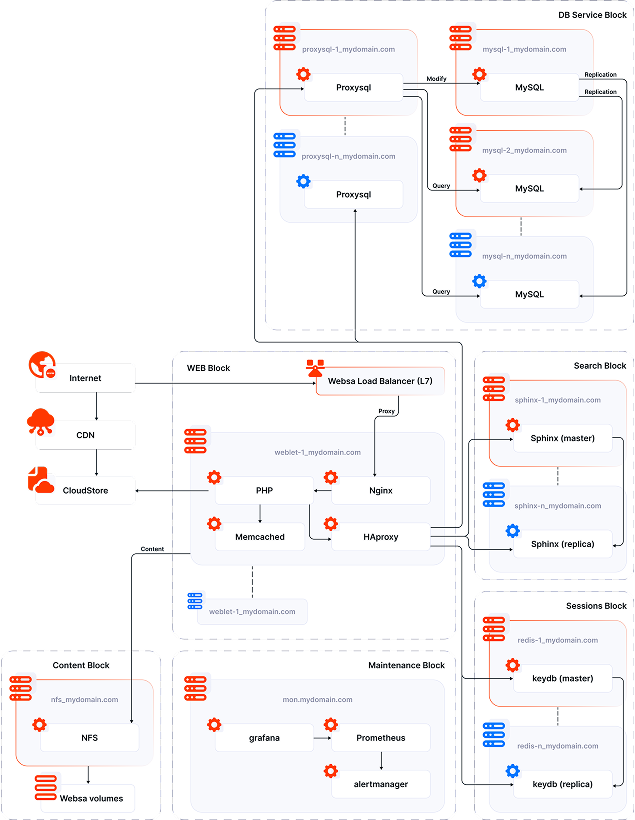
Horizontal Scaling Implementation
- Shifted from vertical scaling (adding more powerful server) towards horizontal scaling (adding more servers).
- Implemented load balancing strategies for efficient traffic distribution.
- Configured a distributed storage system to synchronize data across multiple servers.
Instead of one overloaded server struggling with all tasks, multiple servers now share the load.
These actions gave us clear +400Mb/s traffic for each added node to project with soft CPU usage.
Proactive Monitoring & Support
- Established real-time system monitoring to track CPU, memory, disk, and network usage.
- Implemented predictive alerts, allowing preemptive issue resolution before failures occurred.
- Maintained 24/7 proactive client support, offering continuous optimization suggestions.
- In case of an incident, the new architecture allows us to quickly identify the problem area and act rapidly.
Seamless Deployment Without Downtime
One of the biggest challenges was deploying these changes without disrupting the platform. We executed the migration in stages, gradually shifting traffic to the new infrastructure while keeping the old system running. This ensured that users experienced zero downtime during the transition.
Results & Benefits





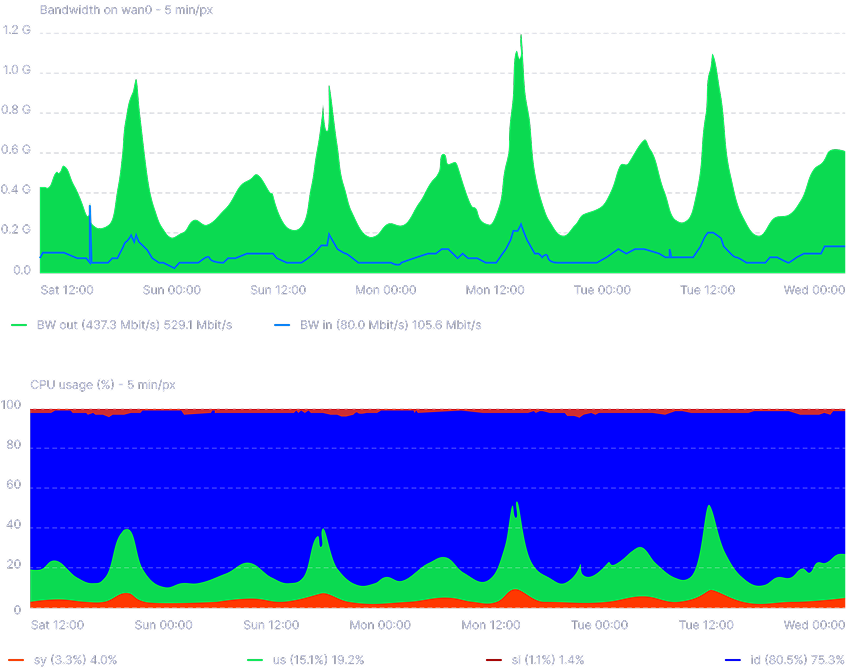
The project grew from the critical 270Mb/s with 100% CPU usage to a regular 1,2Gb/s with comfortable 40% CPU usage, which is an increase of more than 4 times.
*Furthermore, in the case of the last DDoS attack on the project, we confirmed that the service outage occurred due to network capacity overflow, not servers compute ability.
Conclusion
This case demonstrates how businesses can hit limitations due to improper architecture and how the right approach to scaling can prevent major problems. Our experience helps companies avoid these mistakes and build a resilient infrastructure.